Evaluating the Role of Context Representations in the Behavioral Fidelity of LLM-based Personas for Food Preferences
Abstract
Recent work has increasingly relied on LLM-based personas to reason about food preferences, yet the information used to condition these personas is often unstructured, inconsistently represented, or weakly validated. This observation naturally leads to ask whether, and to what extent, LLM-based personas respond to more structured user context representations inspired by those typically adopted in nutritional practice. In this paper, we hence study the role of context representations in the food domain by comparing three forms of context (unstructured, structured, and hybrid) when conditioning LLM-based personas. We evaluate behavioral fidelity by comparing simulated ratings and generated reviews against real user data. Our results show that unstructured text better preserves rating intensity, structured traits alone do not capture preferences well, and hybrid representations yield the most faithful simulations.
Motivation
LLM-based personas have become a popular tool for simulating user behavior, particularly in domains such as food recommendation where collecting real preference data is costly. However, the information used to condition these personas is often unstructured, inconsistently represented, or weakly validated, raising a fundamental question: does the form in which user context is represented actually affect how faithfully an LLM-based persona mimics real user behavior?
The food domain makes this question especially relevant. Nutritional practice relies on structured instruments — questionnaires capturing dietary restrictions, health goals, and food attitudes — that differ substantially from the free-form biographies typically found in user-generated datasets. Yet these two sources of context have never been systematically compared in terms of their impact on persona fidelity.
The Gap: Existing work conditions LLM-based personas on ad hoc or loosely structured user information, without studying whether more principled, nutrition-inspired context representations lead to more faithful simulations of food preferences.
Framework
We design a two-stage pipeline that isolates the effect of context representation on persona behavior.
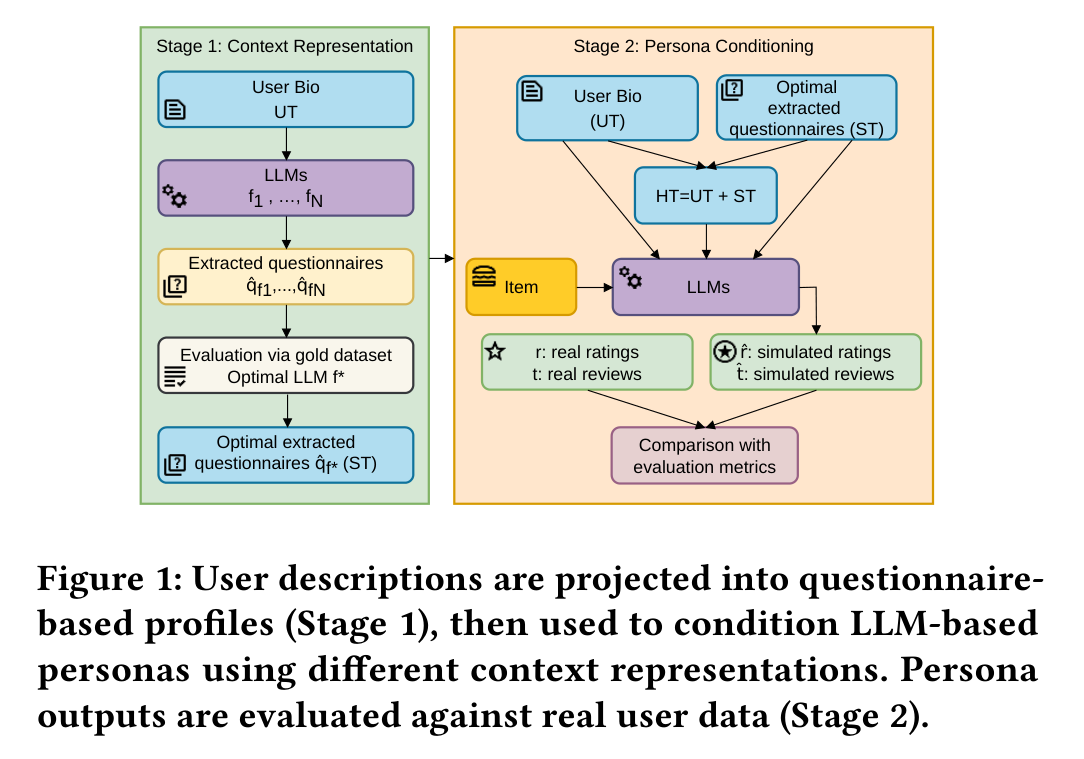
Stage 1: Context Representation
User biographies from the dataset are projected through an LLM into structured profiles derived from two questionnaires:
- Q-lit: A literature-grounded food preference questionnaire covering nine dimensions of food attitudes (familiarity, price, convenience, sensory appeal, health, mood, and others), designed for research settings
- Q-nut: A practitioner-oriented nutrition questionnaire capturing dietary restrictions and health goals, closer to clinical practice
Stage 2: Persona Conditioning
LLMs are conditioned with one of three context representations and prompted to simulate ratings and written reviews for recipes:
- UT (Unstructured Text): Raw user biography in free-form text, directly injected into the prompt
- ST (Structured Traits): Questionnaire-derived structured profile combining Q-lit and Q-nut responses
- HT (Hybrid): Concatenation of UT and ST, combining both information sources
Behavioral fidelity is measured by comparing the simulated outputs against real user ratings and reviews from the dataset, using rating alignment metrics (MSE, MAE, RMSE) and review similarity scores.
Experimental Setup
All experiments are conducted on HUMMUS, the largest publicly available dataset of user-recipe interactions:
- 39,315 users and 507,335 items with an average of 2.84 interactions per user
- 111,654 user-recipe pairs with both numerical ratings and written reviews, used for behavioral fidelity evaluation
We evaluate five open-weight large language models spanning a range of architectures and sizes:
- DeepSeek-R1-70B
- DeepSeek-R1-32B
- Qwen 3-32B
- Qwen 2.5-32B
- LLaMA 3.1-8B
RQ1: Context Projection Quality
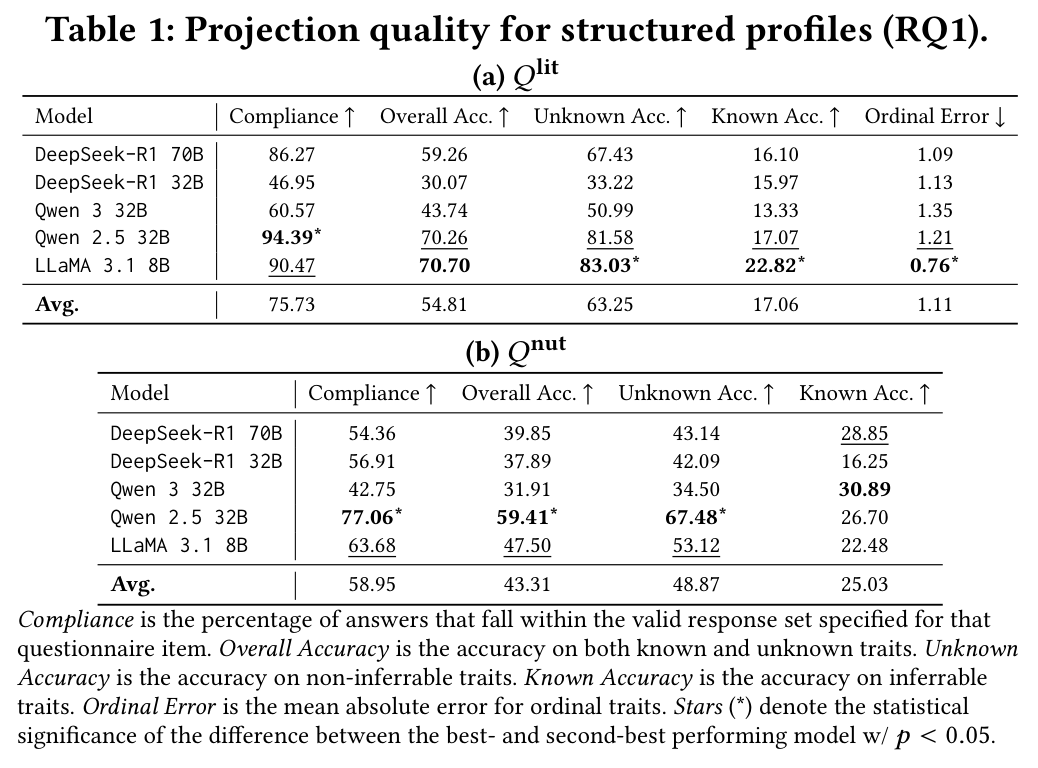
Before conditioning personas, we assess how reliably LLMs can project unstructured user biographies into the structured questionnaire formats (Q-lit and Q-nut). We measure compliance with the response schema, overall accuracy, accuracy on known and unknown answers, and ordinal error.
Key Findings
- Compliance is not guaranteed: Generating schema-compliant structured answers varies substantially across models, indicating that structured projection is a non-trivial task
- Best performers: Qwen 2.5-32B achieves the highest compliance on Q-lit; LLaMA 3.1-8B also performs competitively
- Q-nut is harder: Compliance is uniformly lower on Q-nut than Q-lit, reflecting its higher semantic complexity and clinical specificity
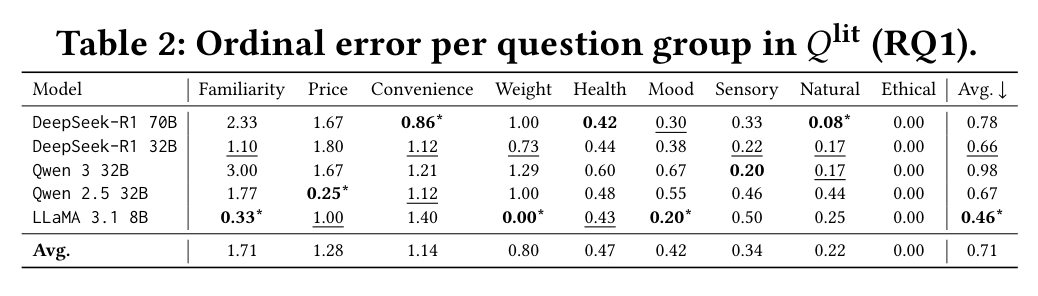
- Dimension-level variation: Familiarity, price, and convenience dimensions show strong heterogeneity in ordinal error; health, mood, and sensory dimensions are inferred with lower error
RQ2: Behavioral Fidelity
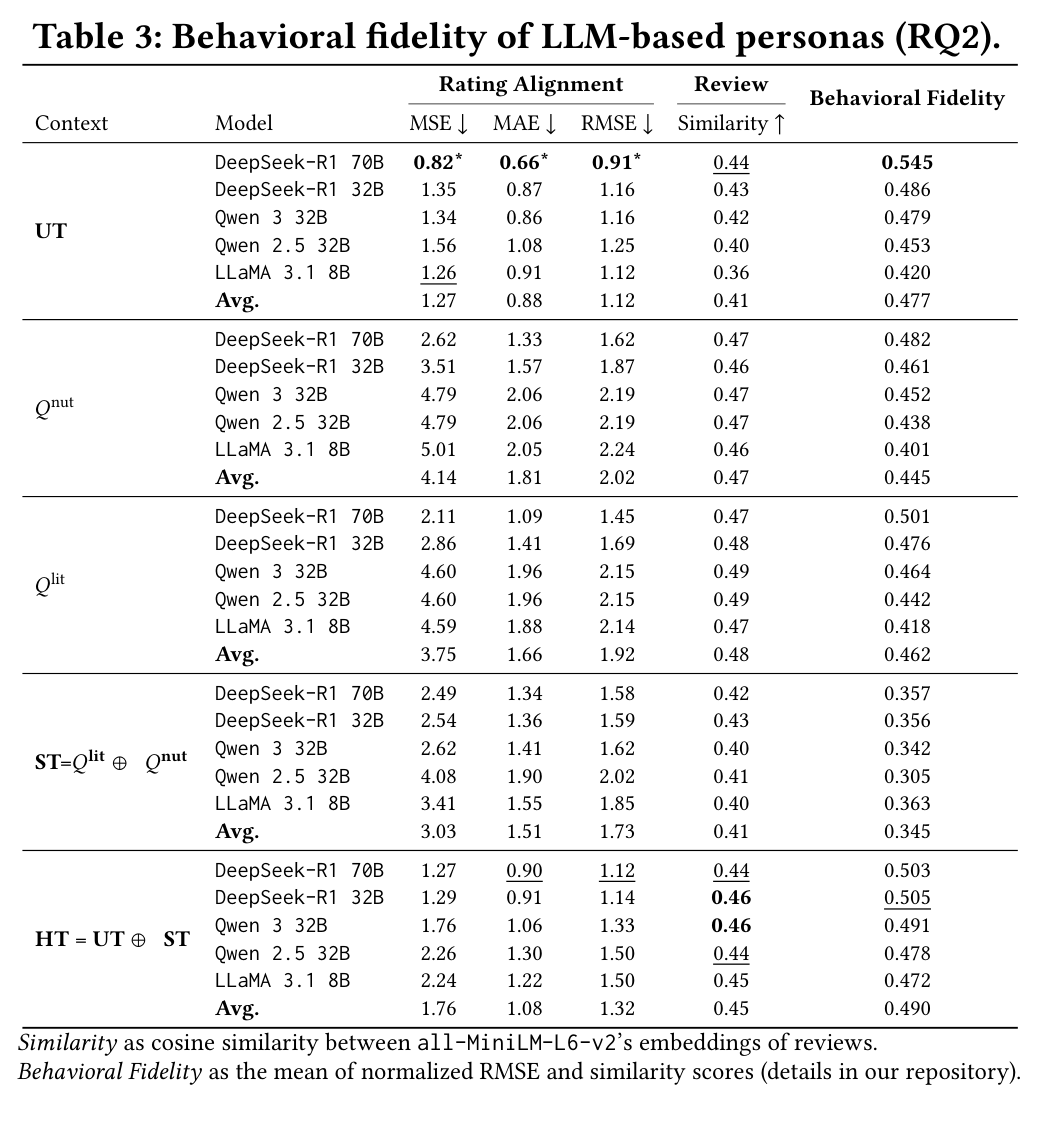
We condition each of the five LLMs with the five context representations (UT, Q-nut, Q-lit, ST, HT) and compare simulated ratings and reviews against real user data.
Key Findings
- UT yields the lowest rating error: Unstructured text consistently achieves the best MSE, MAE, and RMSE across all models — free-form biographies preserve sufficient signal for predicting preference intensity
- Structured contexts improve review quality: Q-lit and Q-nut lead to higher rating error but produce reviews with stronger similarity to real user-written text
- HT achieves the highest overall fidelity: The hybrid representation combines the rating accuracy of UT with the review quality of structured traits, yielding the most consistent simulations
- Model-level differences: DeepSeek-R1-70B tends to over-predict ratings when conditioned on explicit traits; LLaMA 3.1-8B better matches the sparsity patterns of real user ratings
Key Result: How user context is represented has a substantial impact on persona behavior. Unstructured text better preserves rating intensity, structured traits alone are insufficient to capture nuanced preferences, and hybrid representations yield the most faithful simulations overall.
Key Contributions
- Systematic Comparison: First study comparing unstructured, structured, and hybrid context representations for conditioning LLM-based personas in the food domain
- Nutrition-Inspired Questionnaires: Design and evaluation of two complementary questionnaires (Q-lit and Q-nut) grounded in food science and nutritional practice
- Two-Stage Evaluation Pipeline: A reusable framework separating context projection quality (RQ1) from persona behavioral fidelity (RQ2)
- Empirical Evidence on Context Impact: Quantitative evidence that representation choice significantly affects both rating alignment and review similarity across five LLMs
- Hybrid Representation Advantage: Demonstration that combining unstructured and structured context yields more consistent persona behavior than either form alone
BibTeX
@inproceedings{balloccu2026evaluating,
author = {Balloccu, Eleonora and Boratto, Ludovico and Geninatti Cossatin, Angelo and Marras, Mirko and Mauro, Noemi and Medda, Giacomo},
title = {Evaluating the Role of Context Representations in the Behavioral Fidelity of LLM-based Personas for Food Preferences},
booktitle = {Proceedings of the 34th ACM Conference on User Modeling, Adaptation and Personalization},
series = {UMAP '26},
year = {2026},
location = {Gothenburg, Sweden},
publisher = {ACM},
doi = {10.1145/3774935.3806159}
}