Abstract
The recent pandemic Coronavirus Disease 2019 (COVID-19) led to an unexpectedly imposed social isolation, causing an enormous disruption of daily routines for the global community and posing a potential risk to the mental well-being of individuals. However, resources for supporting people with mental health issues remain extremely limited, raising the matter of providing trustworthy and relevant psychotherapeutic content publicly available. To bridge this gap, this paper investigates the application of information retrieval in the mental health domain to automatically filter therapeutical content by estimated quality. We have used AnnoMI, an expert annotated counseling dataset composed of high- and low-quality Motivational Interviewing therapy sessions. First, we applied state-of-the-art information retrieval models to evaluate their applicability in the psychological domain for ranking therapy sessions by estimated quality. Then, given the sensitive psychological information associated with each therapy session, we analyzed the potential risk of unfair outcomes across therapy topics, i.e., mental issues, under a common fairness definition. Our experimental results show that the employed ranking models are reliable for systematically ranking high-quality content above low-quality one, while unfair outcomes across topics are model-dependent and associated low-quality content distribution. Our findings provide preliminary insights for applying information retrieval in the psychological domain, laying the foundations for incorporating publicly available high-quality resources to support mental health.
Motivation
The COVID-19 pandemic forced people into prolonged isolation, limiting human interactions and leading to increased psychological issues such as anxiety and depression. While psychologists and remote therapy access became increasingly important, these services remain cost-intensive and often inaccessible. Furthermore, common people lack familiarity with mental health issues, putting them at risk of encountering misinformative content online.
This study aims to facilitate individuals in autonomously evaluating therapeutical content personalized for their psychological issues through information retrieval (IR) methods. IR can help address mental health issues by:
- Efficiently providing relevant and reliable information
- Personalizing treatment options based on specific needs
- Monitoring mental health trends in the population
Problem Formulation
We model an IR task where:
- Documents = therapy sessions (specifically, therapist utterances)
- Queries = psychological topics (mental health issues)
- Relevance labels = therapy quality (high/low)
Given a query representing a psychological disease, the system retrieves therapeutical content ranked by estimated quality, with the goal of providing high-quality content in higher positions to support patients.
Fairness Definition
We operationalize Demographic/Statistical Parity: the likelihood of relevant content should be the same for any psychological disease. Unfairness is measured as the disparity of ranking utility (NDCG@k) across topics:
\[DS = \frac{1}{\binom{|S|}{2}} \sum_{1 \leq i < j \leq |S|} \|NDCG_i@k - NDCG_j@k\|_2^2\]Dataset: AnnoMI
We used AnnoMI, the first publicly accessible dataset in the psychology domain, containing:
- 133 expert-annotated Motivational Interviewing (MI) therapy sessions
- 44 psychological topics (e.g., smoking cessation, anxiety management)
- 9,695 utterances labeled by therapy quality
After preprocessing (filtering utterances < 5 tokens, removing topics without both quality classes), we obtained 3,984 utterances across 8 psychological topics.
| Topic | Low Quality | High Quality |
|---|---|---|
| Adhering to Medical Procedure (AMP) | 2.36% | 7.83% |
| Asthma Management (AM) | 0.66% | 3.12% |
| Compliance with Rules (CR) | 0.43% | 9.50% |
| Diabetes Management (DM) | 0.18% | 11.45% |
| Managing Life (MF) | 0.86% | 12.18% |
| Reducing Alcohol Consumption (RAC) | 7.14% | 24.95% |
| RAC—Smoking Cessation (RAC—SC) | 0.51% | 0.66% |
| Smoking Cessation (SC) | 3.70% | 14.49% |
Models
We evaluated a diverse set of neural rankers covering different levels of network complexity:
- Arc-I, Arc-II — Convolutional architectures for text matching
- DRMMTKS — Deep Relevance Matching Model
- DUET — Distributed and local text representations
- Dense Baseline, Naive — MatchZoo baselines
- HBMP — Hierarchical Bi-LSTM with Max Pooling
- KNRM — Kernel-based Neural Ranking Model
- TFR-BERT — BERT-based ranker (most complex)
Results
RQ1: Ranking Utility in Psychological Domain
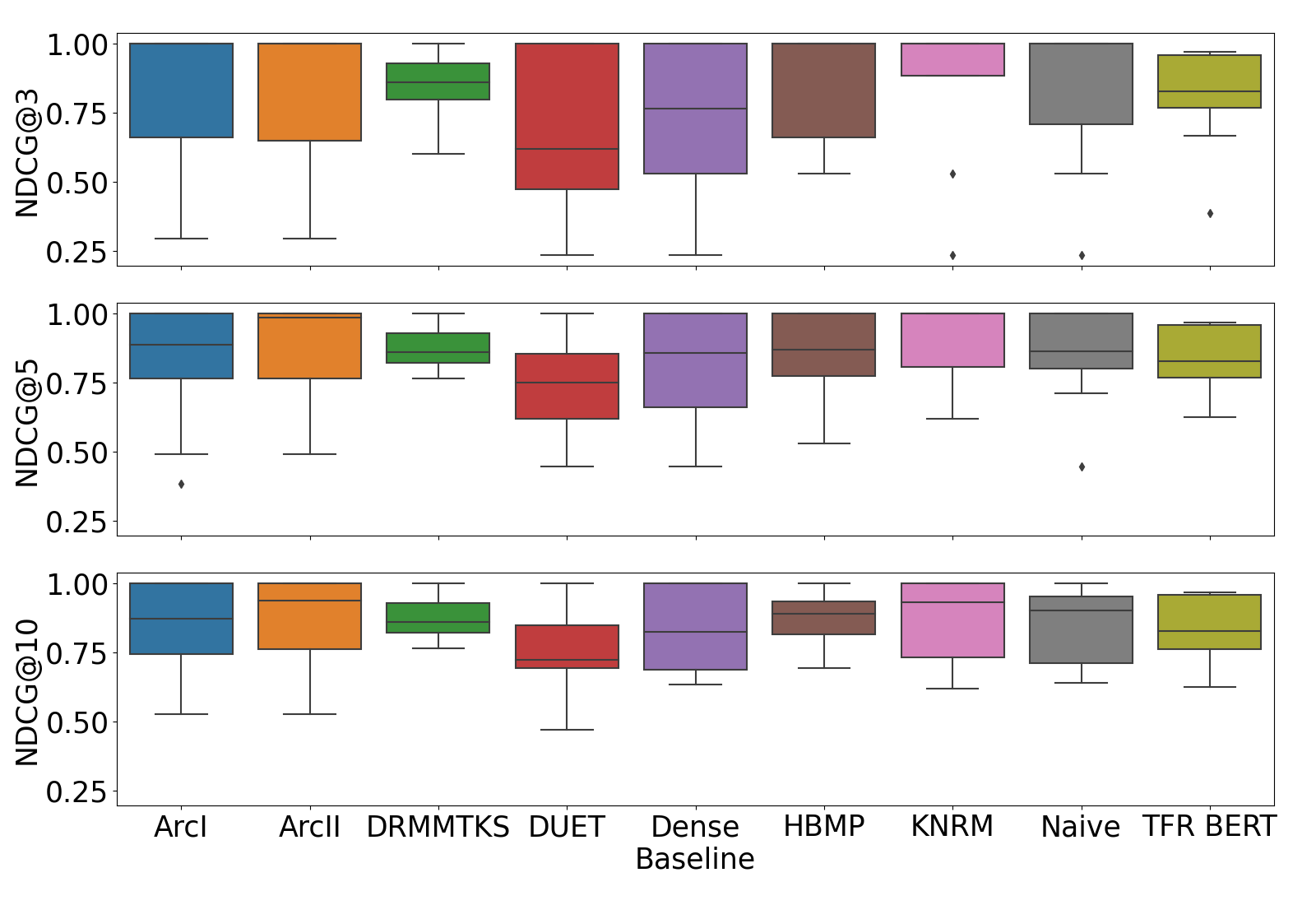
Key findings:
- All models report rankings of high utility on therapeutical data
- DRMMTKS and TFR-BERT are most robust across different k values
- No clear relationship between model complexity and performance
RQ2: Unfairness Levels across Topics
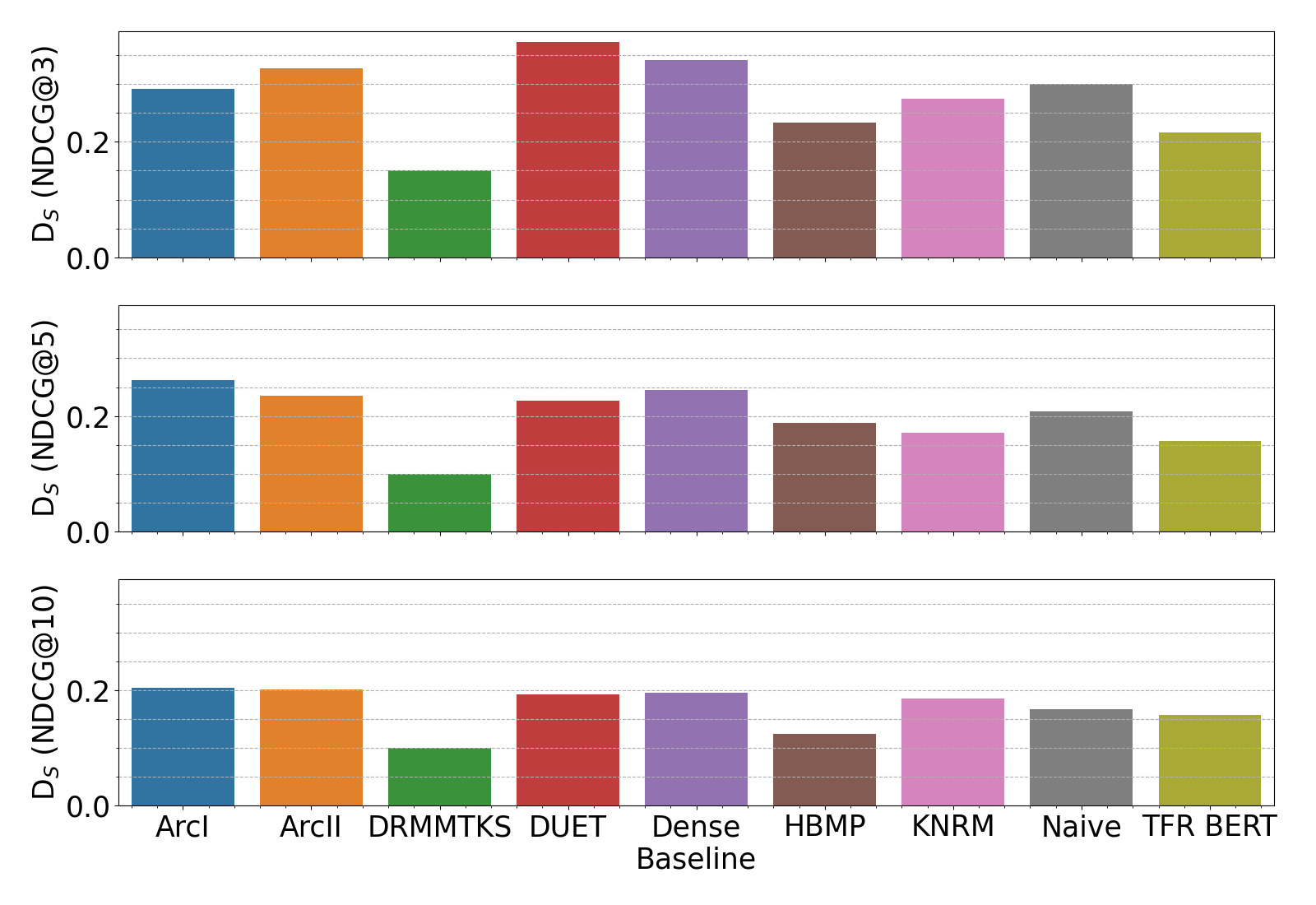
Key findings:
- DRMMTKS, TFR-BERT, HBMP report the best fairness levels
- DUET, Arc-I exhibit the highest unfairness
- Even the fairest models show ~0.1 NDCG disparity between topic pairs
- Top-3 rankings reveal significant utility variance, meaning some queries result in low-quality content
RQ3: Systematic Negative Impact
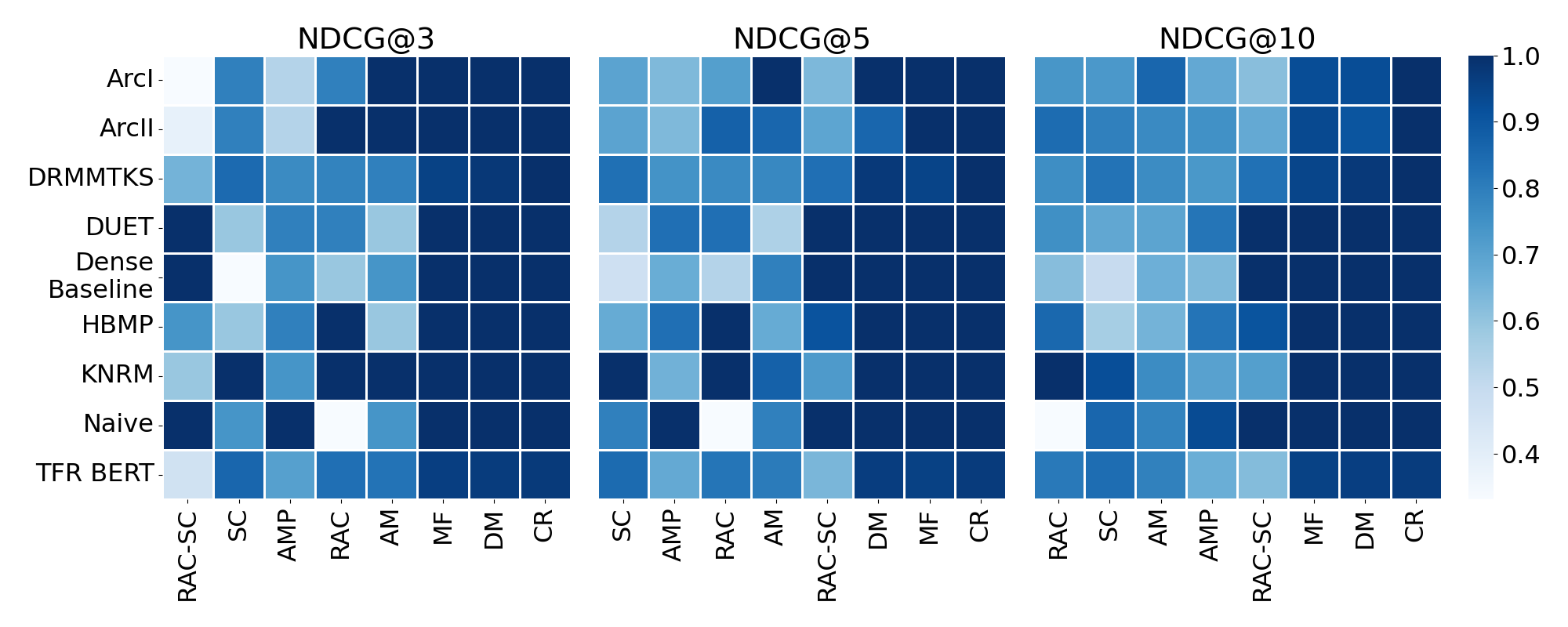
Key findings:
- Topics with higher representation of high-quality utterances (CR, DM, MF) consistently achieve better rankings
- Topics with >1% low-quality documents (SC, RAC, AMP) show lower utility
- No systematic negative impact on specific diseases — at least one model provides optimal utility for each query
Conclusions
- IR is applicable to psychological domain: All ranking models achieved high utility on therapeutical counseling data
- Fairness issues exist: Significant utility disparity across topics for most models
- Unfairness correlates with data distribution: Topics with more low-quality utterances show lower ranking performance
- No systematic bias: Different models exhibit varying performance across topics
Limitations
- Small dataset size (AnnoMI is the only publicly available resource)
- Individual utterances used instead of whole therapy sessions
- Topics without both quality classes were excluded
Future Work
- Data augmentation techniques to extend AnnoMI
- Unfairness mitigation procedures
- Incorporation of world knowledge (knowledge graphs)
- Extension to entire therapy session ranking
BibTeX
@inproceedings{kumar2023feel,
author = {Kumar, Vivek and Medda, Giacomo and Reforgiato Recupero, Diego and Riboni, Daniele and Helaoui, Rim and Fenu, Gianni},
title = {How Do You Feel? Information Retrieval in Psychotherapy and Fair Ranking Assessment},
booktitle = {Advances in Bias and Fairness in Information Retrieval - 4th International Workshop, BIAS 2023},
series = {Communications in Computer and Information Science},
volume = {1840},
pages = {119--133},
publisher = {Springer},
year = {2023},
doi = {10.1007/978-3-031-37249-0_10}
}