Abstract
Most food recommender systems aim to boost user engagement by analyzing recipe ingredients and users’ past choices. Even though consumers are paying more attention to sustainability, such as carbon and water footprints, there remains a notable lack of public corpora that combine detailed user–recipe interactions with reliable environmental impact data. This gap makes it hard to build recommendation tools that both match people’s tastes and help reduce ecological damage. To this end, we present GreenFoodLens, a resource that enriches HUMMUS, one of the largest corpora for food recommendation, with environmental impact estimates derived from the hierarchical taxonomy of the SU-EATABLE-LIFE project. We achieved this result through a multi-step process involving human annotations, iterative labeling assessments, knowledge refinement, and constrained generation techniques with large language models.
Motivation
Why sustainability in food recommendation? Food production accounts for over 26% of global greenhouse gas emissions. Food recommender systems could promote environmentally-conscious choices, but existing datasets lack environmental impact information. GreenFoodLens bridges this gap by enriching the largest food recommendation corpus with sustainability labels.
Resource Description
GreenFoodLens enriches 421,956 recipes (from HUMMUS) with two environmental metrics sourced from SU-EATABLE-LIFE:
- Carbon Footprint (CFP): kg CO₂ equivalent per kg of food (greenhouse gas emissions)
- Water Footprint (WFP): Liters of water per kg of food (water consumption in production)

Methodology
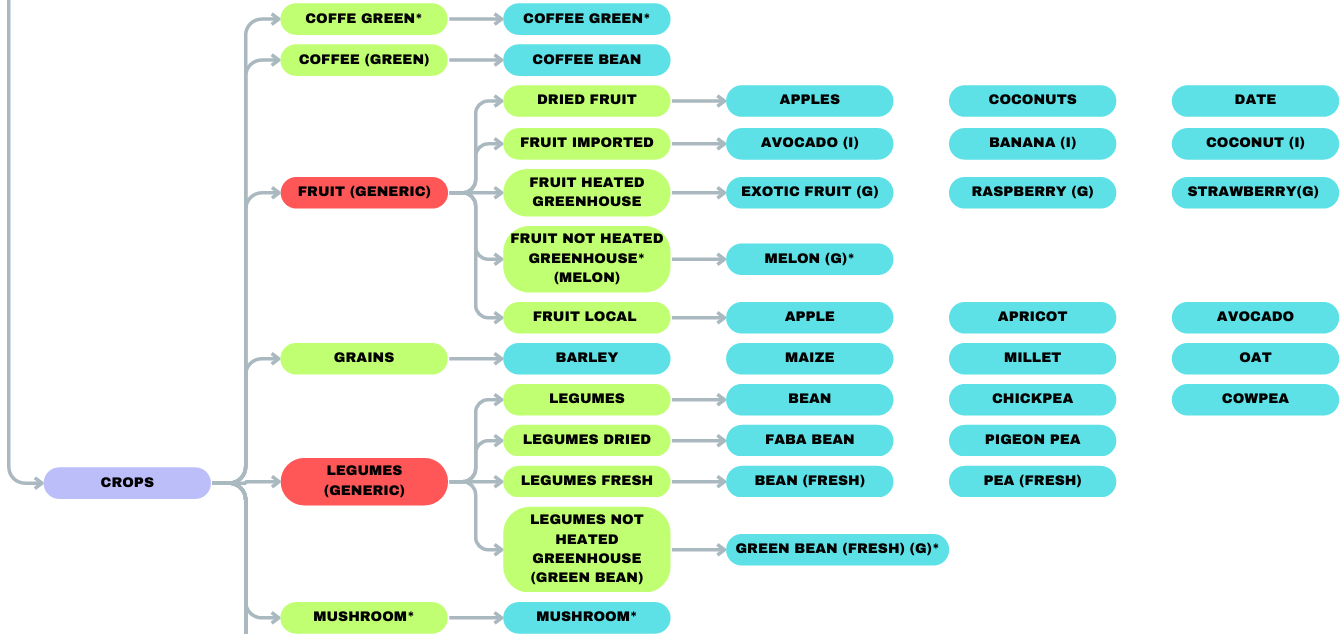
1. Taxonomy Revision
We expanded SU-EATABLE-LIFE's four-level hierarchy (groups → typologies → sub-typologies → items) by:
- Splitting ANIMAL HUSBANDRY into MEAT PRODUCTS and ANIMAL DERIVED for clearer categorization
- Adding intermediate nodes (e.g., YEAST GENERIC) to reduce annotator uncertainty
2. Human Labeling
We collected annotations via Amazon Mechanical Turk for 17,312 unique ingredients (86,560 jobs). After thorough manual verification, we retained 3,496 high-quality annotations as our ground truth.
3. LLM-Based Constrained Generation
We use Large Language Models with grammar-based constrained generation (GBNF) to prevent hallucinations and ensure outputs strictly follow the taxonomy structure. Our approach combines:
- Few-shot prompting: Demonstrating desired output format
- Generate-knowledge prompting: Creating bootstrap descriptions for context
Results & Analysis
Labeling Accuracy
Using Athene-V2-Chat (72B parameters), we achieve strong accuracy at higher taxonomy levels:
- Group Match: 96.22%
- Typology Match: 74.94%
- Sub-typology Match: 55.72%
- Item Match: 51.49%
Dataset Statistics
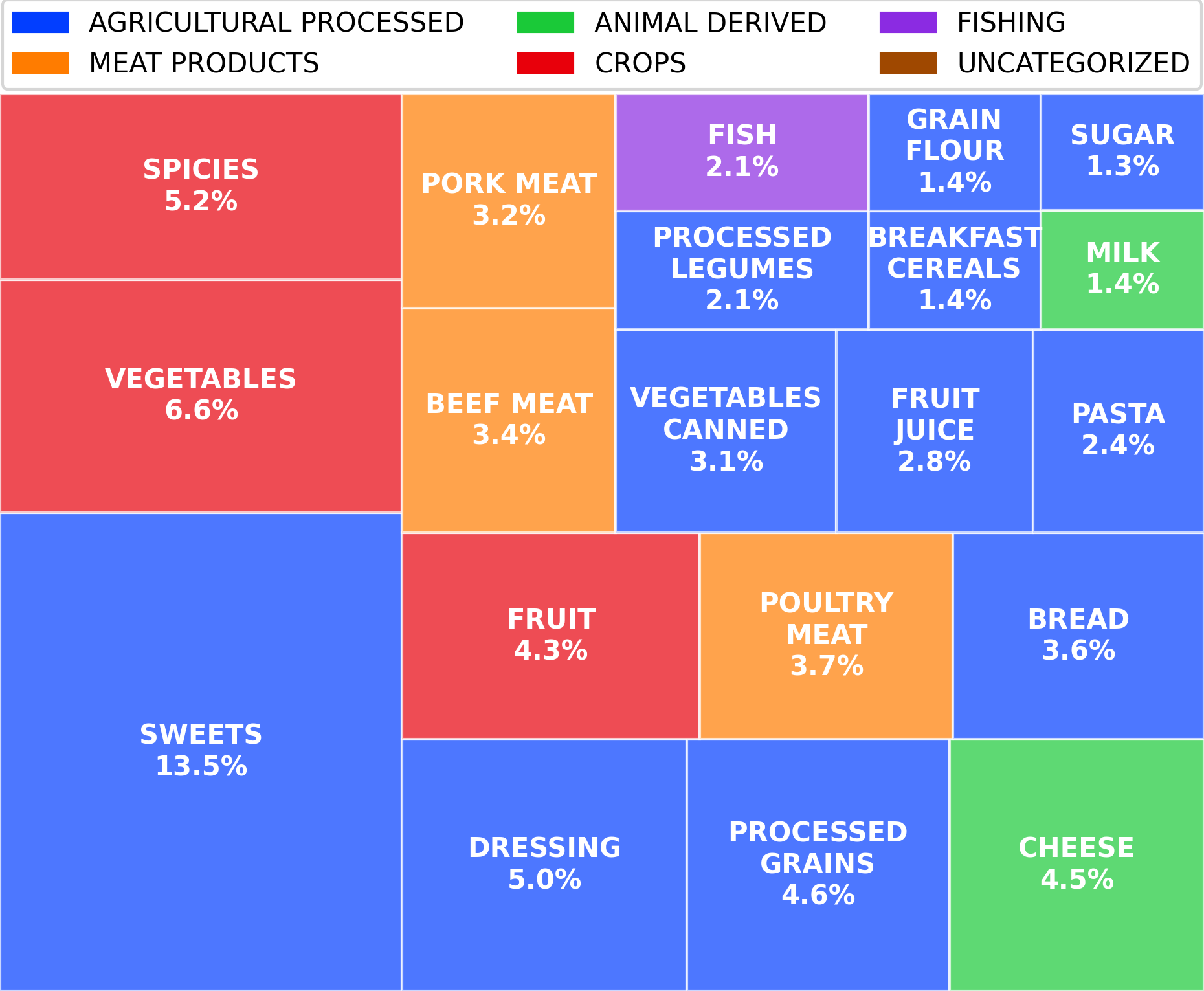
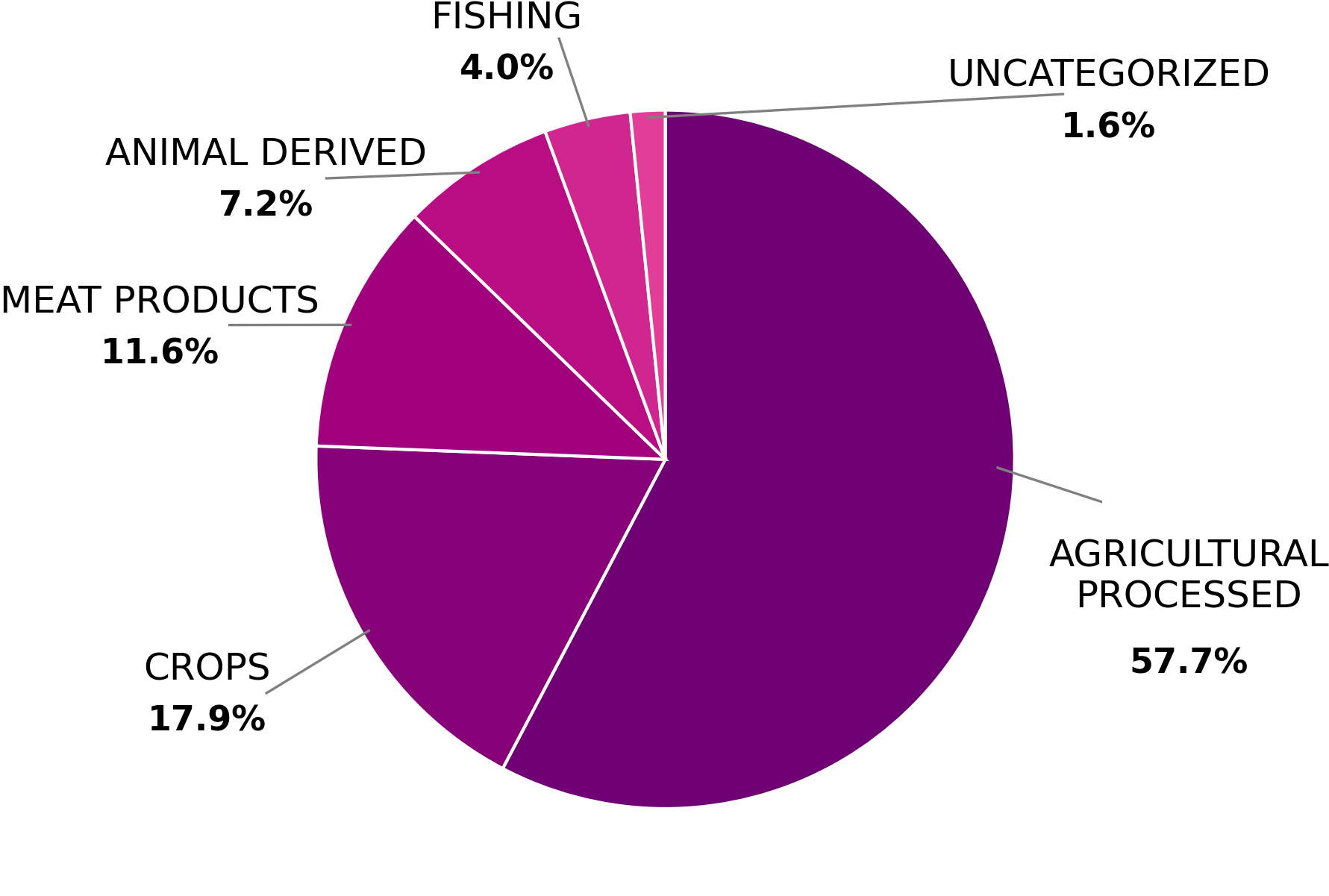
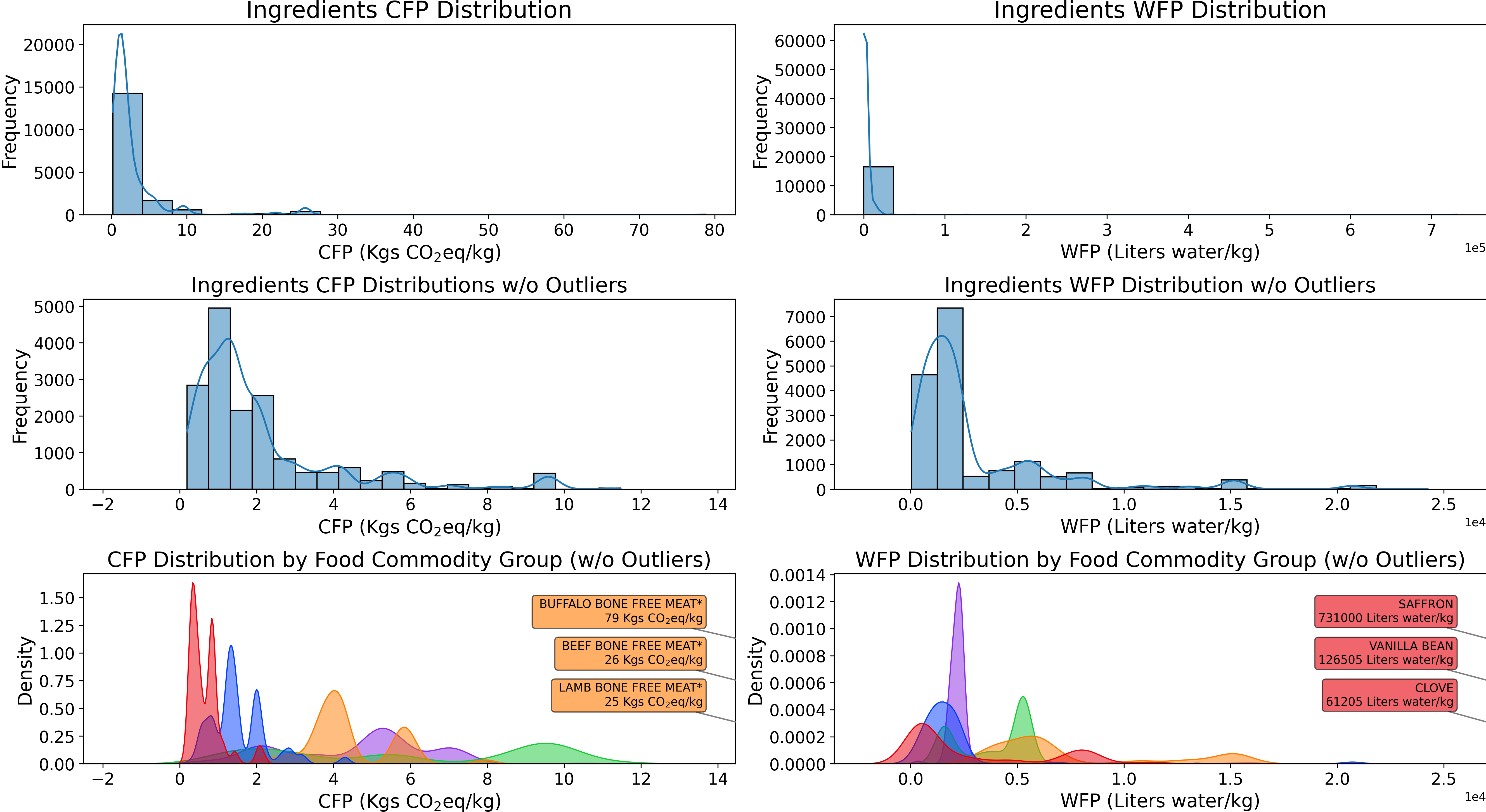
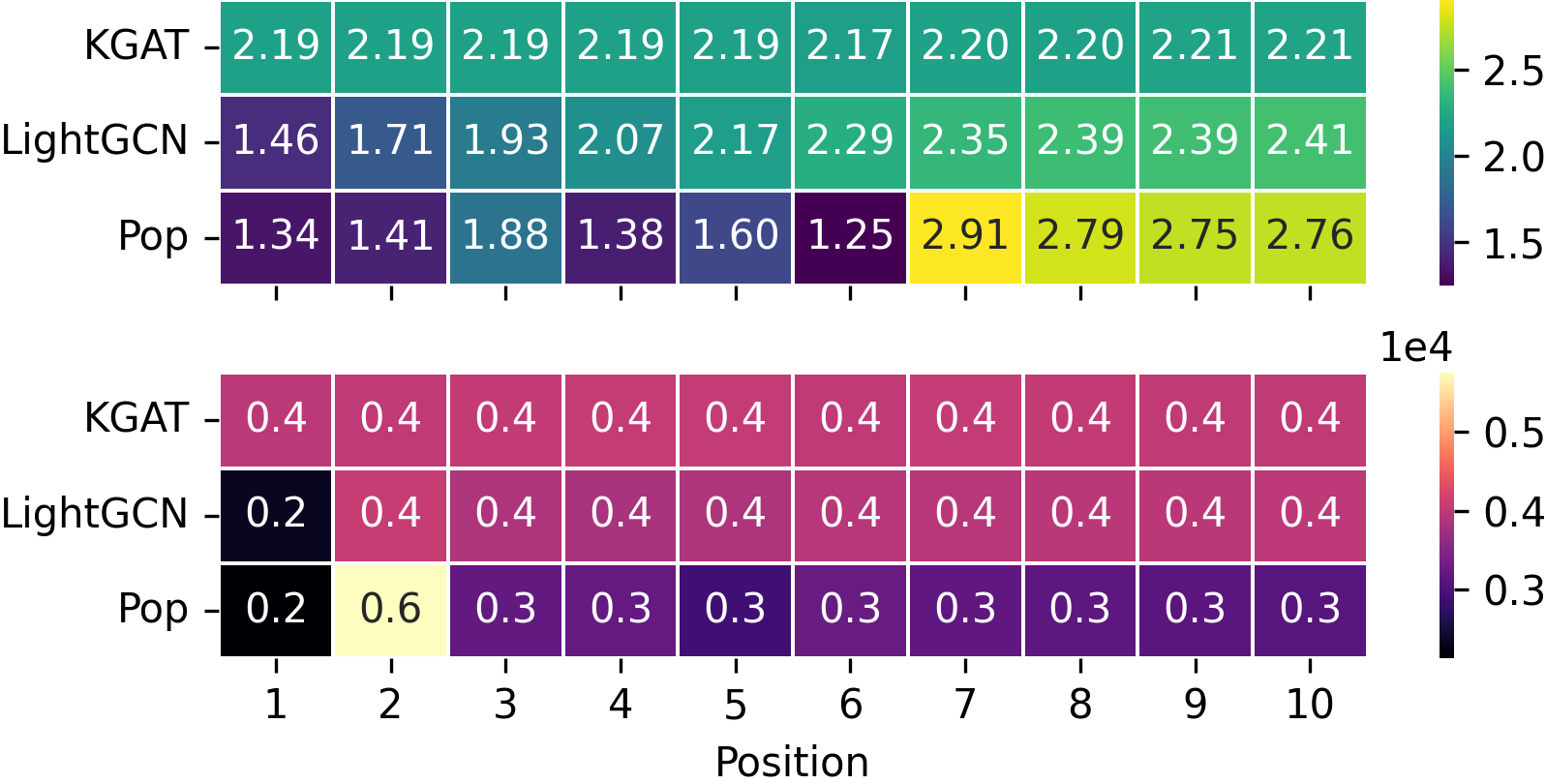
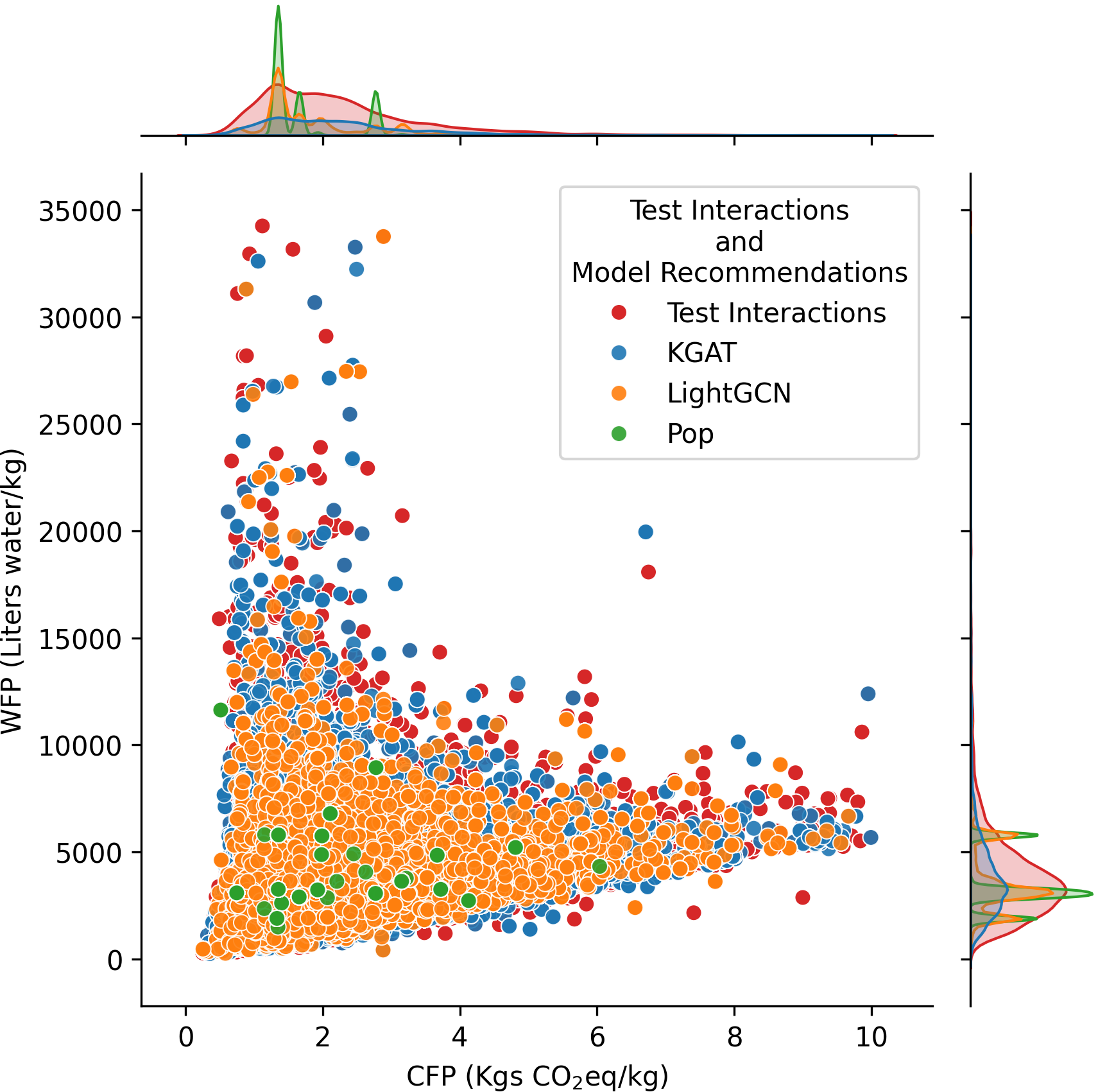
Top-left: Ingredient distribution across food groups. Top-right: 20 most frequent typologies. Bottom: CFP/WFP distributions and recommendation sustainability analysis.
Key Findings
- Most ingredients belong to AGRICULTURAL PROCESSED and CROPS (lower environmental impact)
- SWEETS is the most frequent typology, reflecting dessert popularity on food platforms
- MEAT PRODUCTS and ANIMAL DERIVED show higher CFP/WFP values with pronounced outliers
- Recommendation models are driven by popularity signals, which may exacerbate environmental impact
Applications
Research Directions: GreenFoodLens enables sustainability-aware meal planning, explainable recommendations with environmental justifications, personalized sustainability reports, and product reformulation guidance for food producers seeking lower-impact ingredient substitutes.
BibTeX
@inproceedings{balloccu2025greenfoodlens,
author = {Balloccu, Giacomo and Boratto, Ludovico and Fenu, Gianni and Marras, Mirko and Medda, Giacomo and Murgia, Giovanni},
title = {GreenFoodLens: Sustainability Labels for Food Recommendation},
booktitle = {Proceedings of the 19th ACM Conference on Recommender Systems},
series = {RecSys '25},
year = {2025},
publisher = {Association for Computing Machinery},
doi = {10.1145/3705328.3748165}
}