Abstract
Voice biometrics are increasingly being exploited for authentication in voice controlled cyber-physical systems. In recent studies, speaker recognition systems have shown to exhibit different performance across demographic groups. However, understanding the reasons behind disparate behavior is still challenging and few works have investigated the causes. In this paper, we propose an explanatory framework aimed to understand how the model performs as voice characteristics change. We evaluate two state-of-the-art speaker encoders on a public large-scale data set, systematically analyzing the impact of more than 20 voice characteristics on the security of the models. Findings of this study, while highlighting the importance of studying fairness, show that voice characteristics related to linguistic aspects are those that mainly explain the unfairness in security.
Motivation
Voice biometrics are increasingly being used for authentication in voice controlled cyber-physical systems, such as smart home devices and conversational agents. However, recent studies have shown that speaker recognition systems exhibit disparate impacts across demographic groups.
- Differences in authentication security rates across gender, age, and language groups
- Prior works focused on detecting unfairness but not on understanding its causes
- Mitigation strategies require knowing why unfairness occurs
Key Insight: We propose an explanatory framework to understand how speaker recognition model performance varies as voice characteristics change, going beyond mere group membership to identify the fine-grained voice properties that cause unfairness.
Method Overview
Our explanatory framework consists of two main phases:
- Speaker Recognition Model Creation: Training state-of-the-art speaker encoders (ResNet-34 and X-Vector) on the FairVoice dataset
- Exploratory Analysis: Building surrogate models to explain how voice characteristics impact authentication security
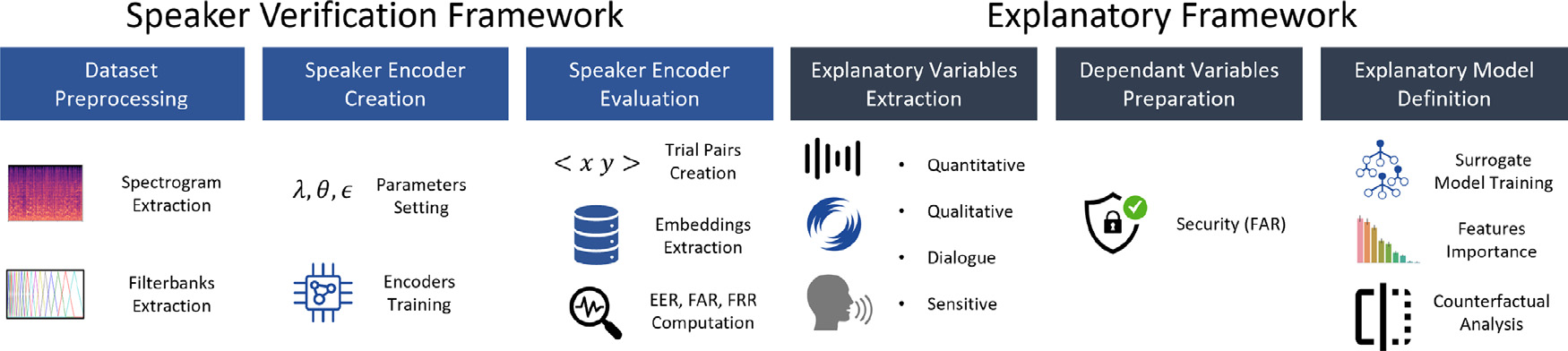
Voice Characteristics
We analyze over 20 voice characteristics, categorized into:
| Category | Type | Characteristics |
|---|---|---|
| Protected | Demographic | Gender, Age Range, Language |
| Non-Protected | Quantitative | RMS, dBFS, SNR |
| Non-Protected | Qualitative | HNR, F0, Formants (F1-F4), Jitter, Shimmer |
| Non-Protected | Dialogue | Syllables, Pauses, Speech Rate |
Experimental Setup
| Component | Description |
|---|---|
| Dataset | FairVoice (derived from Common Voice) - 6,321 English + 1,298 Spanish speakers |
| Speaker Encoders | ResNet-34 (spectrogram input) and X-Vector (filter bank input) with GhostVLAD pooling |
| Surrogate Model | Random Forest (achieving F1 and AUC close to 1) |
| Metric | False Acceptance Rate (FAR) as security measure |
Key Results
Our experiments addressed three research questions:
RQ1: Relationship between explanatory variables
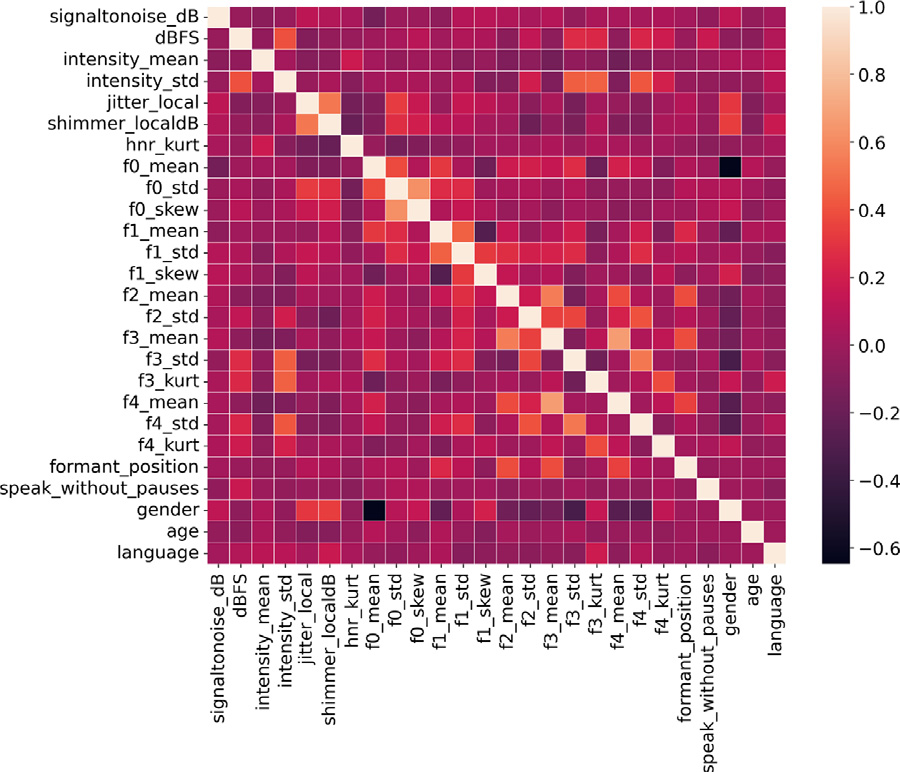
- High correlation between gender and voice characteristics like F0, formants (F1-F4), jitter, and shimmer
- Age and language do not show significant correlation with other speech covariates
RQ2: Influence of speech covariates on performance
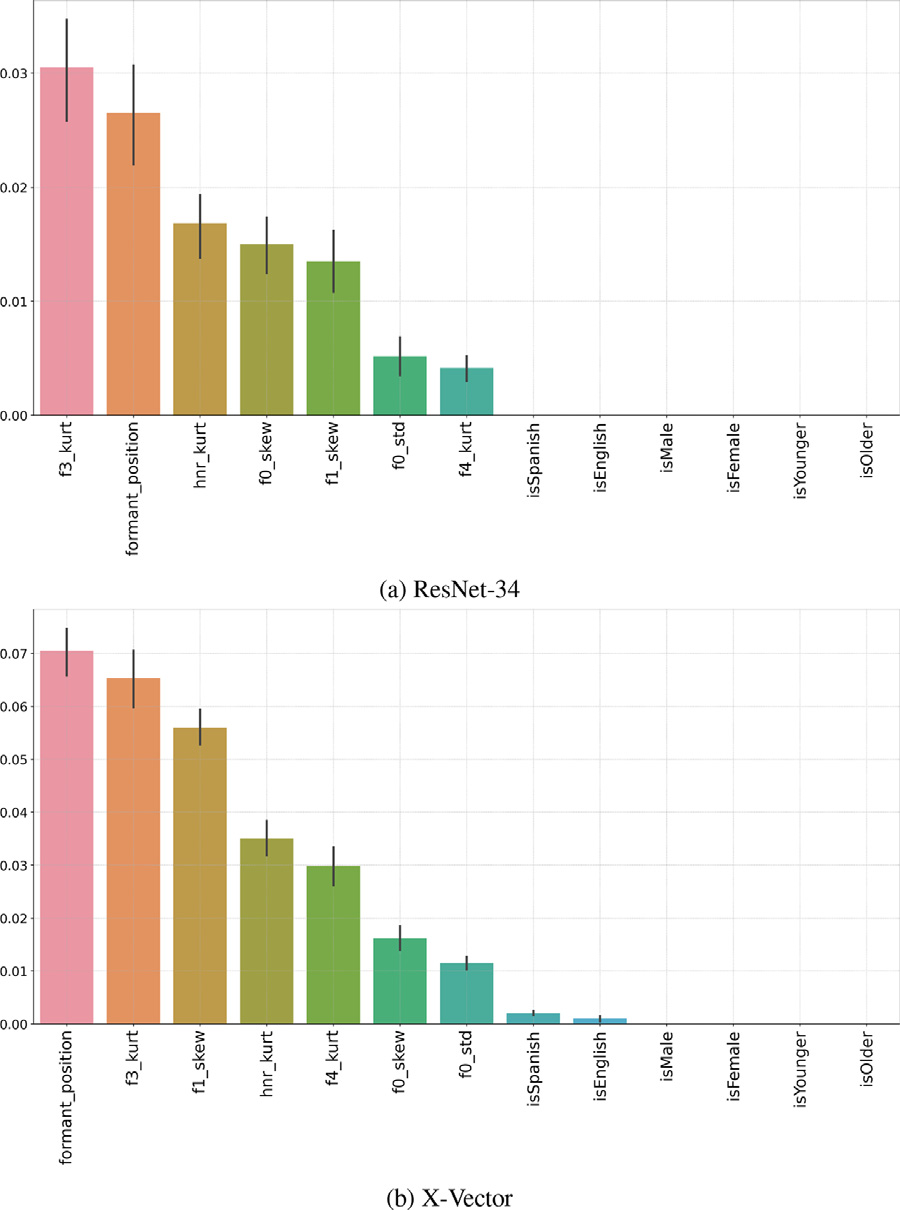
- Formants (F1, F3, F4) and fundamental frequency (F0) are the most important variables for both speaker encoders
- Protected attributes are not directly important for prediction, except for language in X-Vector
- Speech covariates related to vocal frequency aspects explain most of the disparate security estimates
RQ3: Impact of protected class changes
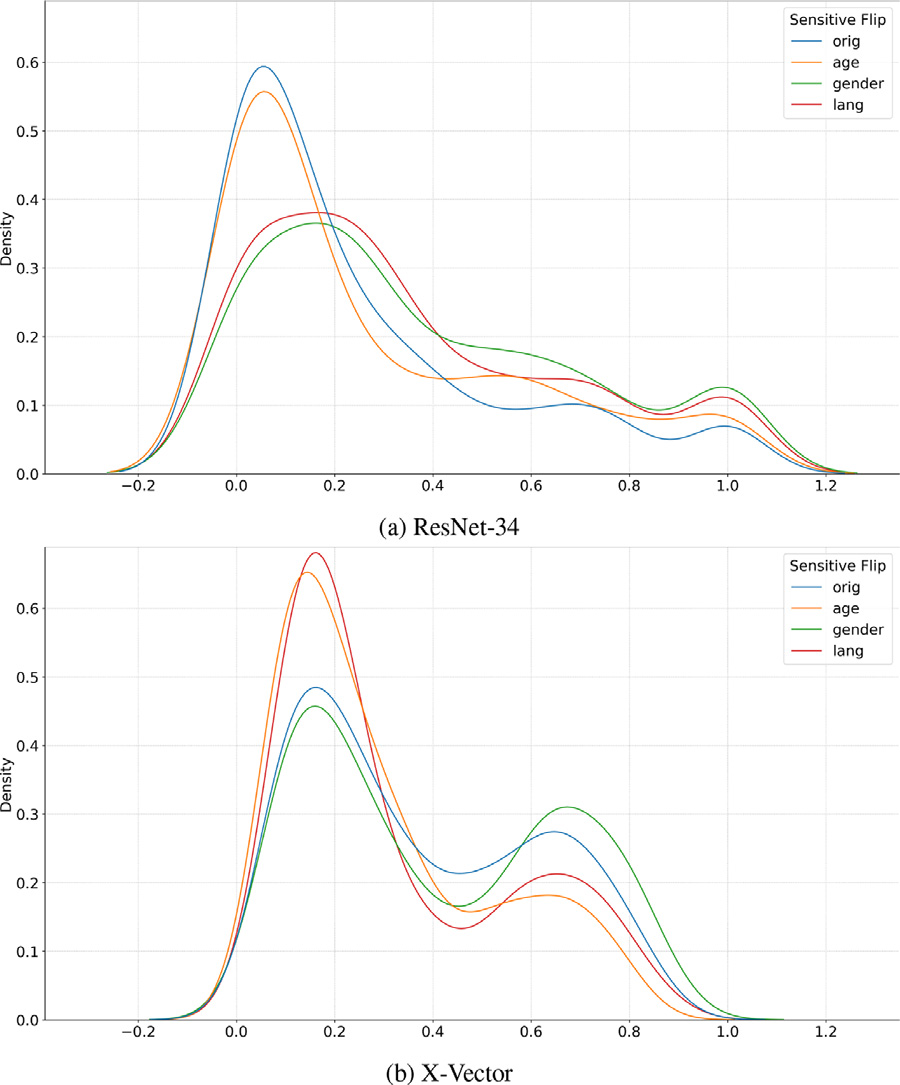
- Flipping gender and language classes resulted in significant FAR changes on ResNet-34
- Flipping language and age classes affected FAR predictions on X-Vector
- Spoken language has the strongest impact on security of both speaker recognition systems
Conclusions
Our findings reveal that:
- Causes of disparate performance go beyond mere membership to demographic groups
- Fine-grained voice characteristics (some related to group membership) are the root causes of unfairness
- These characteristics can serve as proxies for protected attributes that are hard to retrieve due to privacy constraints
Future Directions: Voice covariates can drive specific mitigation strategies (e.g., clustering users based on those characteristics) or input waveform transformations using autoencoders to make speaker encoders robust to these characteristics.
BibTeX
@article{fenu2023causal,
author = {Fenu, Gianni and Marras, Mirko and Medda, Giacomo and Meloni, Giacomo},
title = {Causal reasoning for algorithmic fairness in voice controlled cyber-physical systems},
journal = {Pattern Recognition Letters},
volume = {168},
pages = {131--137},
year = {2023},
publisher = {Elsevier},
doi = {10.1016/j.patrec.2023.03.014}
}